

Abridged: Data as a factor of production
Abridged: Data as a factor of production
On the future of Chinese data governance

Premium subscribers received the full version last week. Subscribe to the get full edition and also notes on Product-Led-Growth and implications for Chinese SaaS this week
Much digital ink has been spilt by lawyers and policy analysts on the exact implications of new regulations in Data Security Law (DSL), Personal Information Protection Law (PIPL), and directives on opening up tech ecosystems. In the mounting analysis, a turn of phrase keeps popping up — data as a factor of production. For me, this cornerstone concept reveals much about China’s future data governance direction and is therefore worth unpacking in detail.
 Complete — Masha Falkov - Art and Glasswork")
On April 9, 2020, the CCP Central Committee issued the "Opinions on Building a More Complete System and Mechanism for Market-oriented Allocation of Factors" (henceforth “Opinions”), where they introduced data as a factor of production alongside land, labour, capital, and technology.1
The "Opinions" put forward the direction that China is creating a market-based allocation mechanism to realise the value generated by data inflow. The Chinese governance apparatus' concern with data is clear — as the digital economy takes a larger share of a country's GDP (in 2020 the digital economy accounted for 38.6% of the Chinese GDP), data governance is governance. China's development state has always taken the stance that markets, societies and economies thrive under defined rules2. The role of the Chinese government is to assist in the creation of effective markets (as expansive as that word entails).
By creating the concept that data is a factor of production, China Inc. has formalised and legislated the stance that data itself is valuable rather than the algorithms it helps train. The Chinese leadership has subtly but deftly implied that data's value to a nation is underpriced and currently subjected to market distortions. A country can unlock credible growth and competitive advantage by harnessing a resource such as data or land through a market-based allocation mechanism. Under this framework, today’s tech giants look similar to the Standard Oil of yesteryear, whose value came from its monopoly of the underlying natural resource. (For readers about to predict that China's going to nationalise big tech, please read on).
This stands in contrast to the piecemeal framework and approaches by western countries and tech firms. While VCs, startups and corporations pay much lip service to the idea that 'data is the new oil,' the talking point is used to indicate that data is valuable to an entity but does not possess inherent value. Legislation such as GDPR is concerned about the protection of privacy as it relates to data. Data is seen as an extension of consumer protection against corporations rather than a resource to be cultivated. Western academic literature discussion of data presents it as a subset of the existing resource category of either labour or capital, which implicitly puts value accretion under the domain of either the firm or the individual. There is little thought to the positive externalities generated by data for a nation.
The Chinese government's definition of data as a factor of production heralds the emergence of a new system of conceptualisation, but it also comes with ambiguity. In current academic literature, data has certain qualities of non-rivalry, partial excludability, increasing returns to scale, externalities and ambiguous property rights.
Non-rivalry - in contrast to traditional sources such as capital, labour or land, one user's data consumption does not reduce its supply to other users. Multiple entities can use the same set of data at the same time.
Partial excludability - Some data can be easily excluded from usage by users while others are not (users can make their data of public weather, say)
Increasing returns to scale (generally) - Goldfarb and Tucker (2019) describe how digitalisation reduces costs in the form of search, replication, transportation, tracking and verification. These lowered costs, coupled with the non-rivalry nature of data and the extensive use of machine learning, increase returns to scale. (Though this attribute has limitations since not all ML recommendations get better indefinitely with additional data.)
Externalities - Reflected in the efficiency improvement of data-collecting enterprises, for example, the more one uses a search engine, the better that product becomes for the user and other users. This is not always positive since the exact mechanism generates a price discrimination mechanism amongst users.
Ambiguous property rights - The distribution of data ownership between users and firms is unclear. Meta-data generated in the process of using technology arguably can belong to many parties.
Readers who still remember their economics basics may recognise that being both non-rivalrous and partially excludable makes data a form of a semi-public good. This means that if a provision is left public in the private domain, without the absence of government intervention, these goods' benefits to society may be unrealised. With government intervention and the provision of a data market, the thinking goes, it could generate an increased net benefit for a society similar to subsidised public universities.
"Today, new production factors such as data have a multiplier effect on the efficiency of other factors, forming advanced productive forces. Particularly, defining data as a new type of production factor in the new document will help energize such a modern production factor, injecting new impetus to promote high-quality development and foster innovation-driven development." - NDRC speaking to China Daily
Beyond the grand concepts and new potential realms of economic breakthrough, policymakers are faced with the reality of how to implement such ideals. It's immediately apparent that there's a tension between the need for personal security, data openness and national oversight. That will involve carefully balancing different actors and interest groups, but that is one of many problems to be solved in a market allocation of data. The reason why digital governance has made such limited progress in the world is apparent; it is a tough thing to do.
What is emerging is the relationship between individual, industrial and national spheres for data is complicated and interconnected. Each level has conflicting motivations with corresponding layers, and those interplay has influenced policy directions so far. I've put together the overlapping themes that affect each layer below.
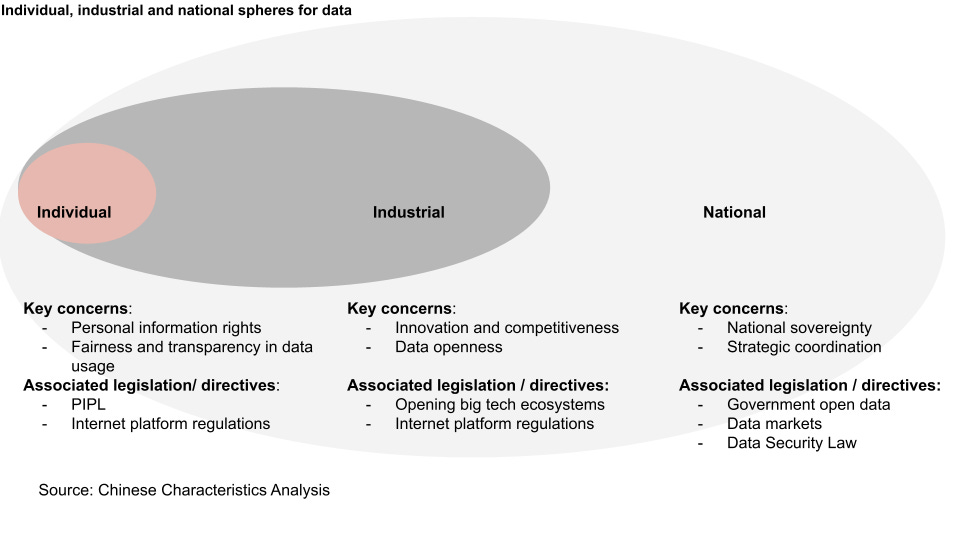
Individual: Data privacy and (partial) ownership - long time readers might know, but illegal sales of personal data is a severe issue in China. Due to lax enforcement and weak security measures, users' personal information is sold to unscrupulous sources with negative results. Extending from the micro to the macro, the wariness around data security is one of the critical hindrances around cloud adoption for both individuals and businesses.
Industrial: Innovation and competitiveness - firms want open but proprietary access to data to ensure competitiveness and build a data moat (in the form of user lock-in).
National: National sovereignty and strategic coordination - The short-term focus is on data sovereignty within and outside China. Mid- to long-term focus is laying down coordination mechanisms and structures to foster a functioning national data market.
The emerging literature has highlighted the following key challenges of creating a market-based exchange for data:
Nebulous ownership structure - Data does not necessarily belong to a specific person or entity. Through continuous derivative data generation, data ownership becomes even more muddled. For example, does my meta-data use related to a search engine belongs to me? What about the meta-data of the algorithm trained on my usage data? Without clear ownership structures, usage rights, management, and transaction rights can not be clearly defined, recognised and protected.
Lack of unified standards and market mechanisms - There are no standardised data values nor cost measurement systems and no agreed-upon pricing structure or trading requirements for data. Information asymmetry of data value is inevitable since data will generate different values under various scenarios. This makes unified data markets hard to establish and gain liquidity. In other words, data is not a standardised good and does not lend itself easily to capitalisation and commercialisation.
Coordination issues across agencies and governments - Across the vast and diverse geographic and economic domains in China, effective coordination has always been complex. With rivalrous resources such as land and capital, authority over allocation is easily localised. With data, this problem becomes complicated quickly. As NRDC notes, the ideological understanding of various industries concerning data is inconsistent, and digitalisation is immature.
At the level of ministries and commissions, more than 60% of the State Council's constituent departments, directly affiliated ad hoc agencies, and directly affiliated institutions have issued big data development documents in corresponding fields (see below) and initiated the construction of the industry's big data centre system. Various ministries and commissions have strengthened data management in their industries, but problems such as silos and duplicated efforts are prominent. Cross-departmental, cross-system and cross-regional coordination are still very difficult. In the future, faced with super large scale data circulation, across a wide range of fields, the current lack of top-down and horizontally connected management and coordination mechanisms will become increasingly prominent.

Twenty-five provinces have also established various forms of big data management agencies, some under the control of the provincial government; others are subordinate to functional ministries such as the NDRC. That’s without going into the various data markets exchanges in different development stages around the country.
Data resides in silos across enterprises and governments - This fact is familiar to any firm undergoing digital transformation, never mind a country. Data resides in silos across organisations, and the simple act of comprehensive and unified data capture is a mighty one. Multiplied across numerous provinces and firms and the issue quickly becomes enormous. Trivium notes that data completeness for social credit records "stored in ten standalone state agency credit databases, compared against the records displayed in the central CSCS files, showed significant gaps in accuracy and completeness...indicating that large gaps still exist in inter-agency data transfer"
Low levels of data security - Sales of personal and enterprise data on the grey market has been lucrative for as long as the law has been lax. Even Apple’s customer data was not immune. The danger of increased data without adequate security is that more of it can end up in the wrong hands, and upsetting the very progress the government is trying to encourage. Without a foundation of data security, it is hard to carry out the lofty commercialisation goals that China wants to achieve.
Through the lens of seeing data as a factor of production, the way I make sense of the current slew of legislation that’s coming out is aiming to commoditise and secure data in a slightly analogous fashion to financial assets. There will need to be clearer ownership structures for individuals, secured national data holdings, and interoperability across databases if data marketplaces are realised. I also predict we will see many start-and-stops as well as new conceptual creations as things unfold.
The current discussion about how to construct policies that capture the complexity of property rights and how to balance protection with innovation is still ongoing. The pragmatism of Chinese governance means that theory and practice never take place sequentially but concurrently. So once again, we're in river-crossing-stone-feeling mode. It is however exciting to behold the arrival of the future, be it good, bad or just weird.
As seasoned policy analysts pointed out, publications with "Opinions" signify major themes put forward by the government. The implications range from testing the waters with the intelligentsia to instructions to be carried out by regional governments. In the context of data, it seems to be landing somewhere in the middle of this spectrum.
Though when the laws and regulations come is a matter of timing and often trial and error
Helpful summary.
The creation of markets reminds me of Tim O'Reilly's article on Government as a Platform, in which he asks "What if, instead of a vending machine, we thought of government as the man- ager of a marketplace?" Though O'Reilly's argument is not exclusively about data, it applies to it.
A point I don't see discussed is the place of public research institutions, e.g. universities, government labs. They appear to sit somewhere at the connection point between the national interest and industrial interests. For a non-nationalized big tech industry, the publicly funded and publicly run universities are a means for indirect influence and governance. Curious what that relation is looking like in China and how it enters the national data strategy.
Lilian, this is a very interesting writeup. I'd be interested in your thoughts on the Solid project (https://solidproject.org/). If you haven't heard of it the exec summary is that it allows for you to store your own data in a "pod". You take your pod from service to service which uses the data you choose to provide and (should) return any generated data to your pod.
My take on it is that it has a nice intent but will not take off in the US since returning generated data removes a lot of service lock in for applications. After reading your article I wonder if a more favorable environment for this would be China. The Chinese government has the ability to regulate the usage of data and close the loop on returning the data. This project would also be a standard to fulfill the overall policy desired of unified standards for transfer and clear data ownership.